关于我
关于我
常见的5种Agent框架实现原理
Agent实现原理
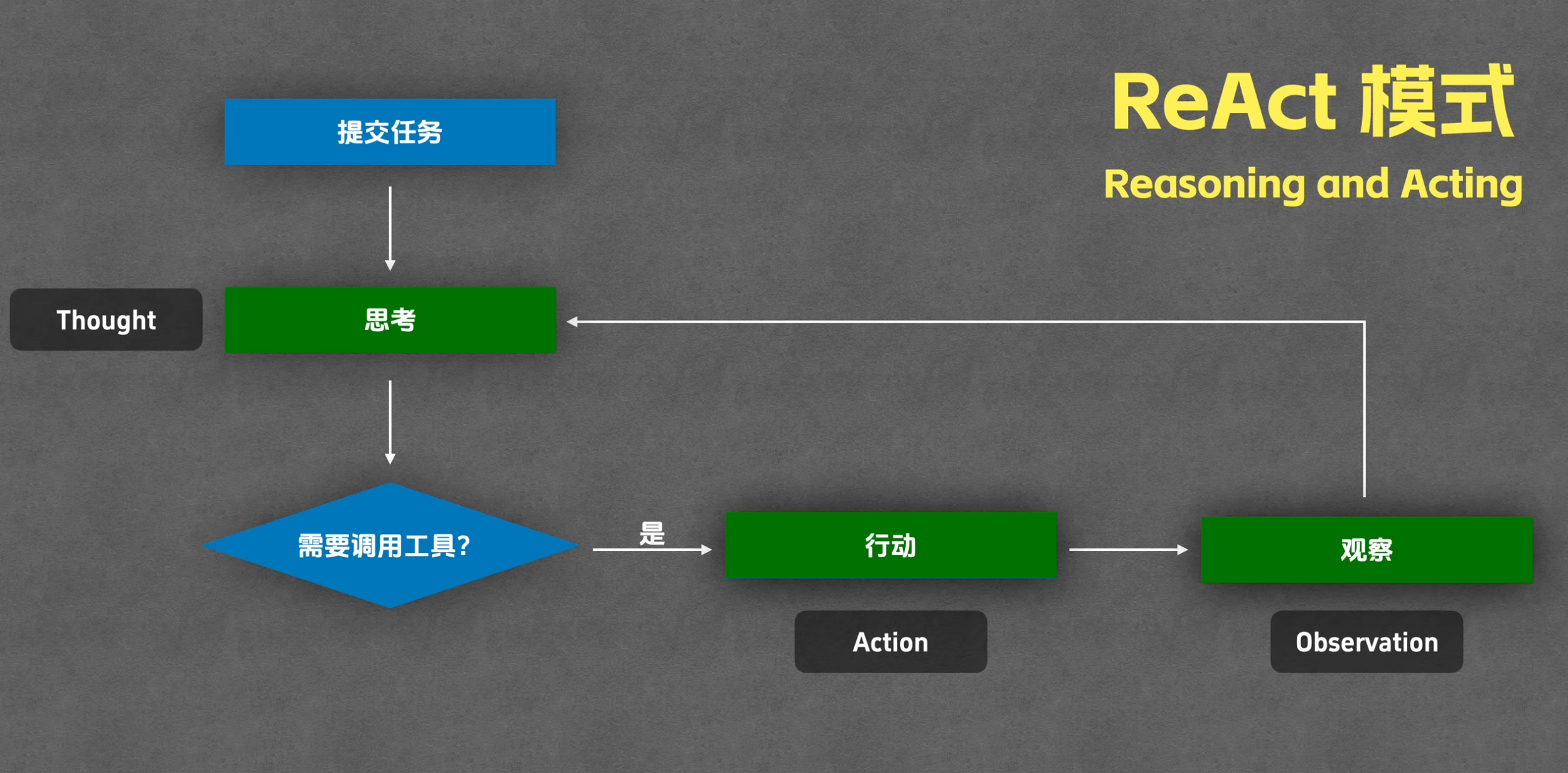
1. ReAct
链接 :<span class="ne-text">https://arxiv.org/abs/2210.03629</span>
简介 : 提出了里程碑式的<span class="ne-text">Thought -> Act -> Observe</span>框架,将“思考”(Reasoning)和“行动”(Acting)深度交织,是现代 Agent 框架与外部世界交互的理论基石。
Reasoning and Acting
核心步骤: Thought->Action->Observation->Final Answer
是靠提示词决定的
react_system_prompt_template = """
你需要解决一个问题。为此,你需要将问题分解为多个步骤。对于每个步骤,首先使用 <thought> 思考要做什么,然后使用可用工具之一决定一个 <action>。接着,你将根据你的行动从环境/工具中收到一个 <observation>。持续这个思考和行动的过程,直到你有足够的信息来提供 <final_answer>。
所有步骤请严格使用以下 XML 标签格式输出:
- <question> 用户问题
- <thought> 思考
- <action> 采取的工具操作
- <observation> 工具或环境返回的结果
- <final_answer> 最终答案
⸻
例子 1:
<question>埃菲尔铁塔有多高?</question>
<thought>我需要找到埃菲尔铁塔的高度。可以使用搜索工具。</thought>
<action>get_height("埃菲尔铁塔")</action>
<observation>埃菲尔铁塔的高度约为330米(包含天线)。</observation>
<thought>搜索结果显示了高度。我已经得到答案了。</thought>
<final_answer>埃菲尔铁塔的高度约为330米。</final_answer>
⸻
例子 2:
<question>帮我找一个简单的番茄炒蛋食谱,并看看家里的冰箱里有没有西红柿。</question>
<thought>这个任务分两步。第一步,找到番茄炒蛋的食谱。第二步,检查冰箱里是否有西红柿。我先用 find_recipe 工具找食谱。</thought>
<action>find_recipe(dish="番茄炒蛋")</action>
<observation>简单的番茄炒蛋食谱:将2个鸡蛋打散,2个番茄切块。热油,先炒鸡蛋,盛出。再热油,炒番茄至软烂,加入鸡蛋,放盐调味即可。</observation>
<thought>好的,我已经有食谱了。食谱需要西红柿。现在我需要用 check_fridge 工具看看冰箱里有没有西红柿。</thought>
<action>check_fridge(item="西红柿")</action>
<observation>冰箱检查结果:有3个西红柿。</observation>
<thought>我找到了食谱,并且确认了冰箱里有西红柿。可以回答问题了。</thought>
<final_answer>简单的番茄炒蛋食谱是:鸡蛋打散,番茄切块。先炒鸡蛋,再炒番茄,混合后加盐调味。冰箱里有3个西红柿。</final_answer>
⸻
请严格遵守:
- 你每次回答都必须包括两个标签,第一个是 <thought>,第二个是 <action> 或 <final_answer>
- 输出 <action> 后立即停止生成,等待真实的 <observation>,擅自生成 <observation> 将导致错误
- 如果 <action> 中的某个工具参数有多行的话,请使用 \n 来表示,如:<action>write_to_file("/tmp/test.txt", "a\nb\nc")</action>
- 工具参数中的文件路径请使用绝对路径,不要只给出一个文件名。比如要写 write_to_file("/tmp/test.txt", "内容"),而不是 write_to_file("test.txt", "内容")
⸻
本次任务可用工具:
${tool_list}
⸻
环境信息:
操作系统:${operating_system}
当前目录下文件列表:${file_list}
"""

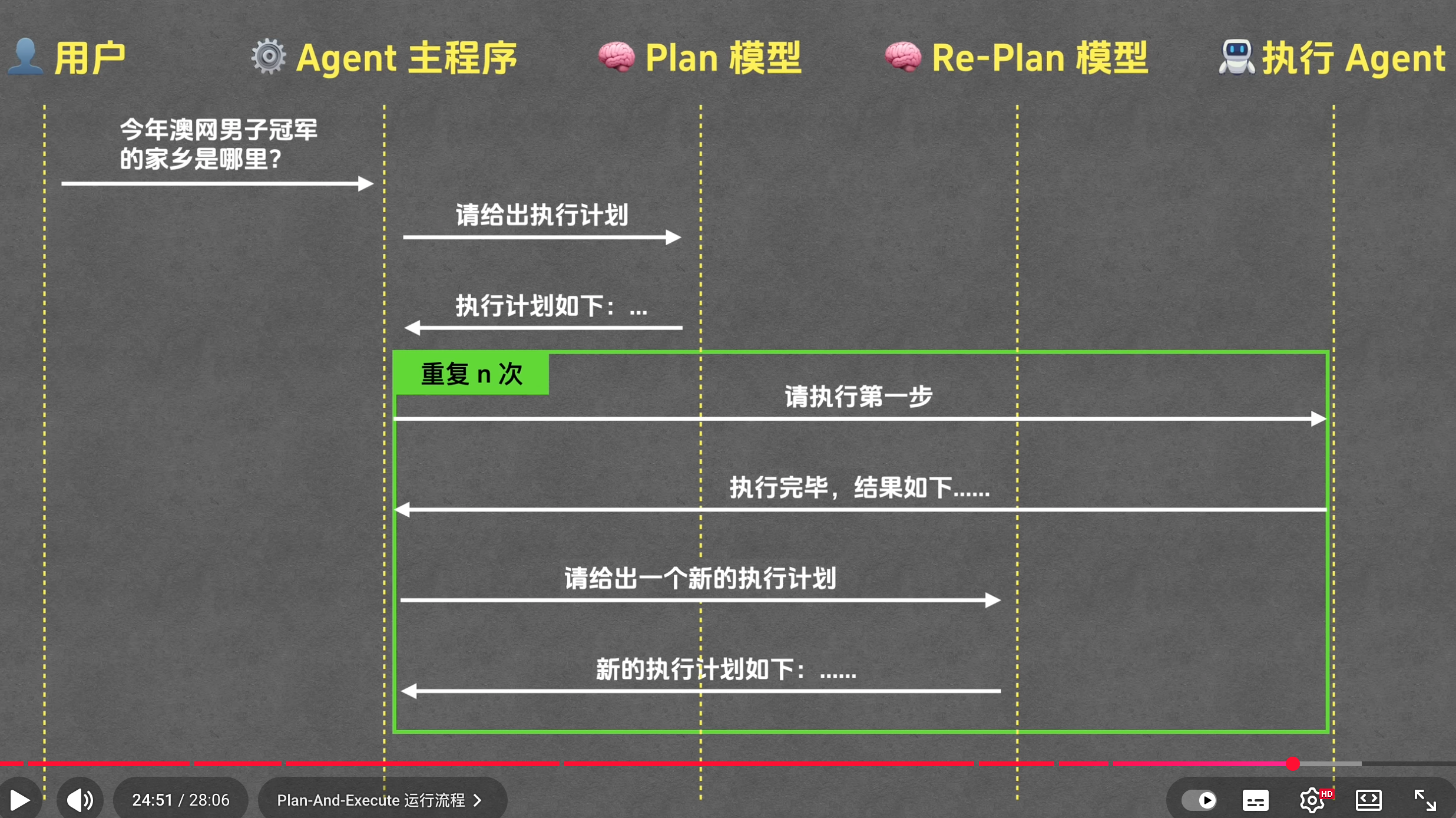
2. Plan-And-Execute


- Agent主程序启动,调用Plan模型生成执行计划
- 主程序交给执行Agent执行
- 主程序根据执行结果让Re-Plan 模型给出新的执行计划
- 进行多轮循环执行,直到任务结束


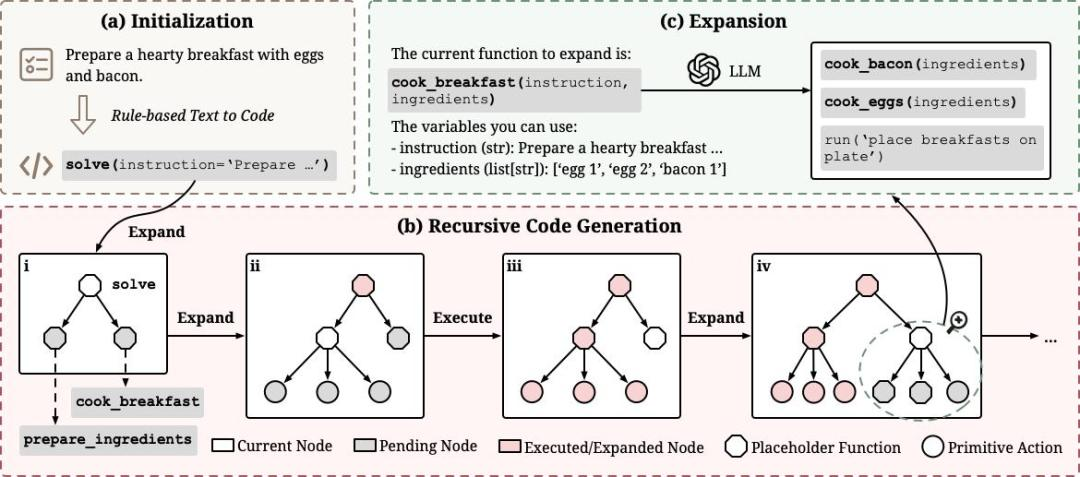
3. ReCode模型
来自 DeepWisdom 的研究员在论文中指出,当前主流智能体框架都被固定的决策粒度束缚住了。ReAct 智能体只会一步步执行细粒度动作,缺乏全局规划;而带规划器(Planner)的智能体虽然能制定高层计划,但规划和执行被硬生生分成两个模块,难以动态调整和优化。
这个问题的根源在哪?论文给出了一个颠覆性的答案:规划和行动本质上是同一件事,只是粒度不同而已。
基于这个洞察,他们提出了 ReCode(Recursive Code Generation) ,一个用递归代码生成来统一规划与执行的智能体新范式。与 ReAct 这类固定粒度的范式不同,ReCode 让智能体能够在不同粒度间自由切换,从而展现出更强的适应性和潜力。

基于这个洞察,ReCode 提出了一个优雅的解决方案: 用统一的代码表征来表示所有决策,无论粒度粗细。 高层计划表示为占位符函数,低层动作表示为可执行函数,然后通过递归机制将前者逐步分解为后者。

https://www.toutiao.com/article/7579912224597377572/?log_from=646f370224834_1765032072637
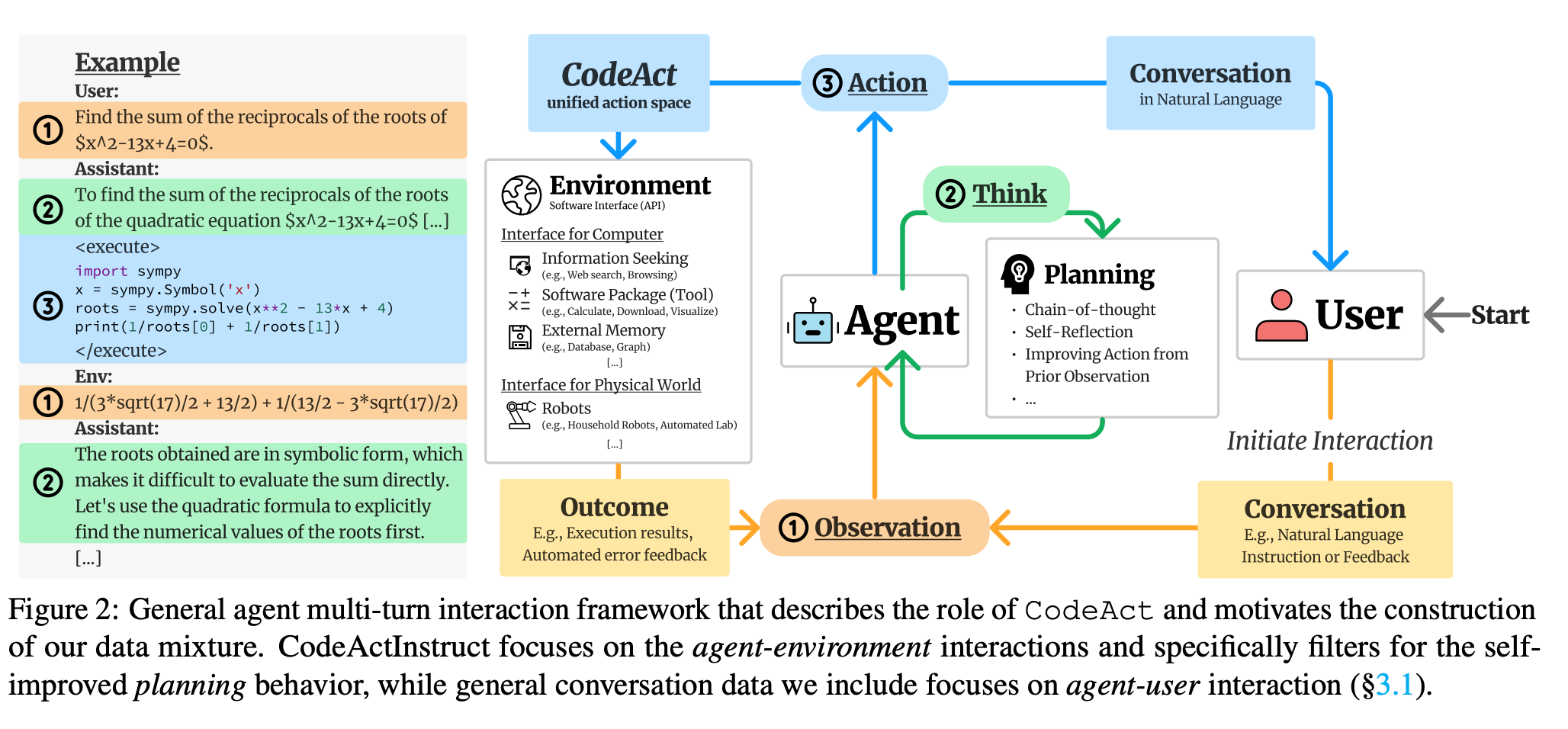
4. CodeAct
标题 : CodeAct: A Multi-Turn Code Agent with In-Context Learning
链接 :<span class="ne-text">https://arxiv.org/abs/2402.01030</span>
简介 : 雄辩地证明了 Agent 的<span class="ne-text">Act</span>环节可以从“调用预定义工具”进化到“即时生成代码并执行”,极大地扩展了 Agent 的能力边界。


Executable Code Actions Elicit Better LLM Agents

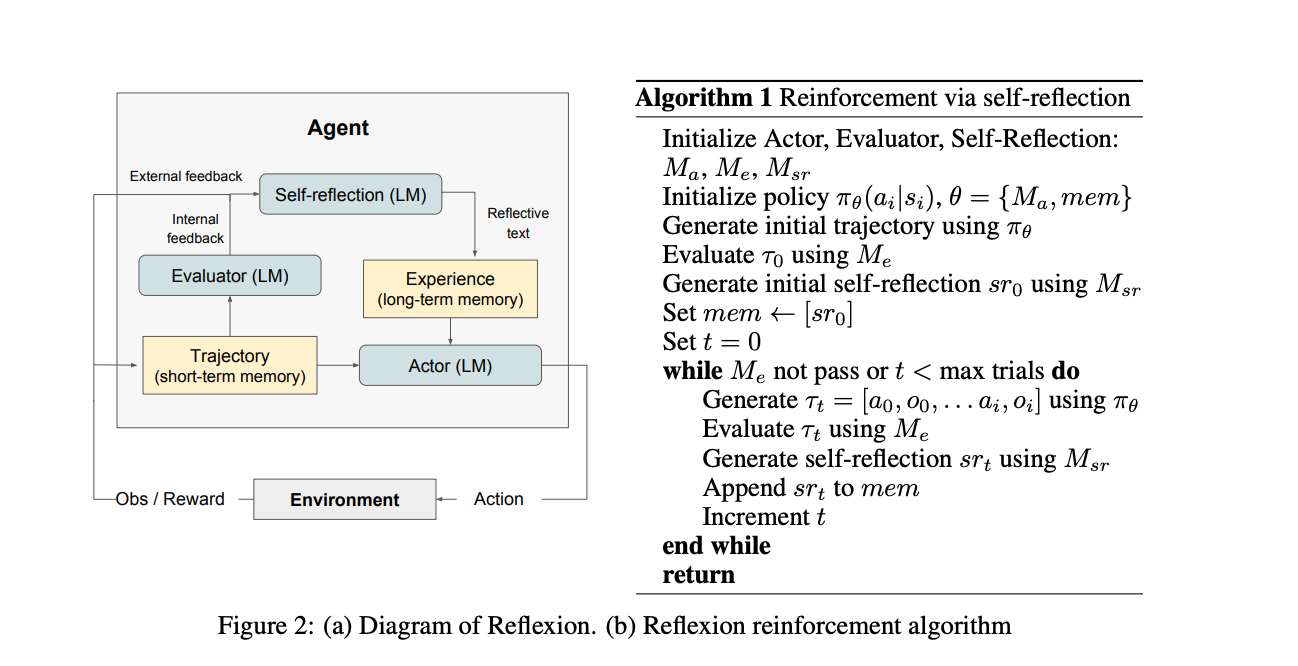
5. Reflexion
标题 : Reflexion : Language Agents with Verbal Reinforcement Learning
链接 :<span class="ne-text">https://arxiv.org/abs/2303.11366</span>
简介 : 首次将“自我反思/复盘”这一概念框架化、自动化。它证明了 Agent 可以通过对过往失败进行“语言反思”来迭代优化自身行为,而无需重新训练模型。